Experiments with MCP
Late to the bandwagon, but I’ve been playing around with MCP servers a lot lately. At first, I was just using existing ones, but then I hit a few cases where nothing out there really fit what I needed. So I ended up building a few myself. In this post, I’ll talk about three of them.
MCP for fitnotes app
If you lift, you should be logging your workouts. And if you're logging your workouts, there's no better app than FitNotes (Android, iOS). The devs behind the two versions are different, but they’ve made the apps cross-compatible, which is great if you ever switch between Android and iOS.
Hooking into the data was actually pretty simple. The app lets you take periodic backups of the “Android DB,” which is just a SQLite database. I wrote a small bash script that moves that file from the iCloud folder into the project directory.
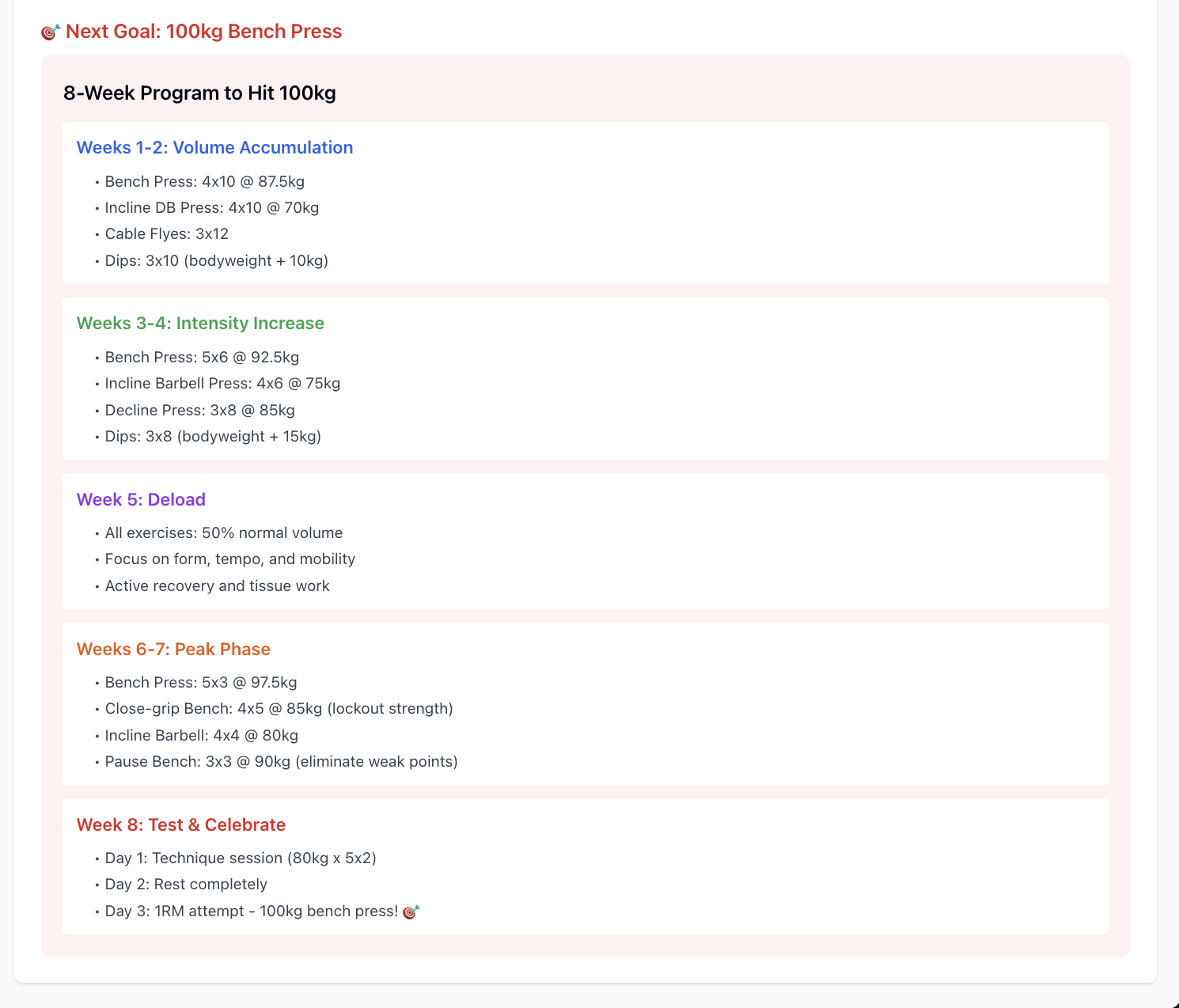
Out of everything I’ve built, this is easily the most useful MCP server. If you’ve got a solid amount of data in FitNotes, you can basically turn your LLM into a personal coach. Ask it to spot trends, suggest improvements, and help fine-tune your training.
Example analysis that i did with this MCP
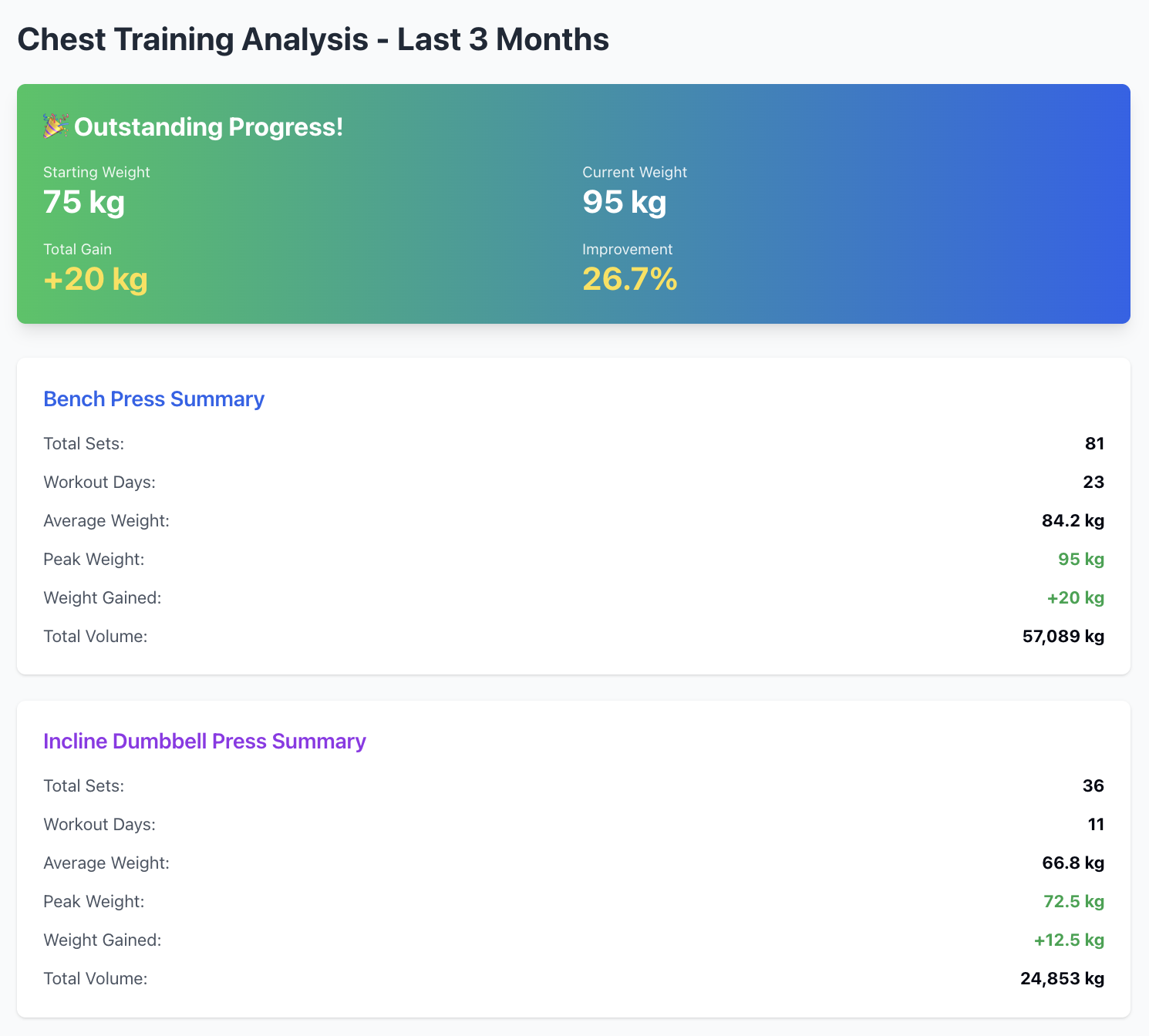
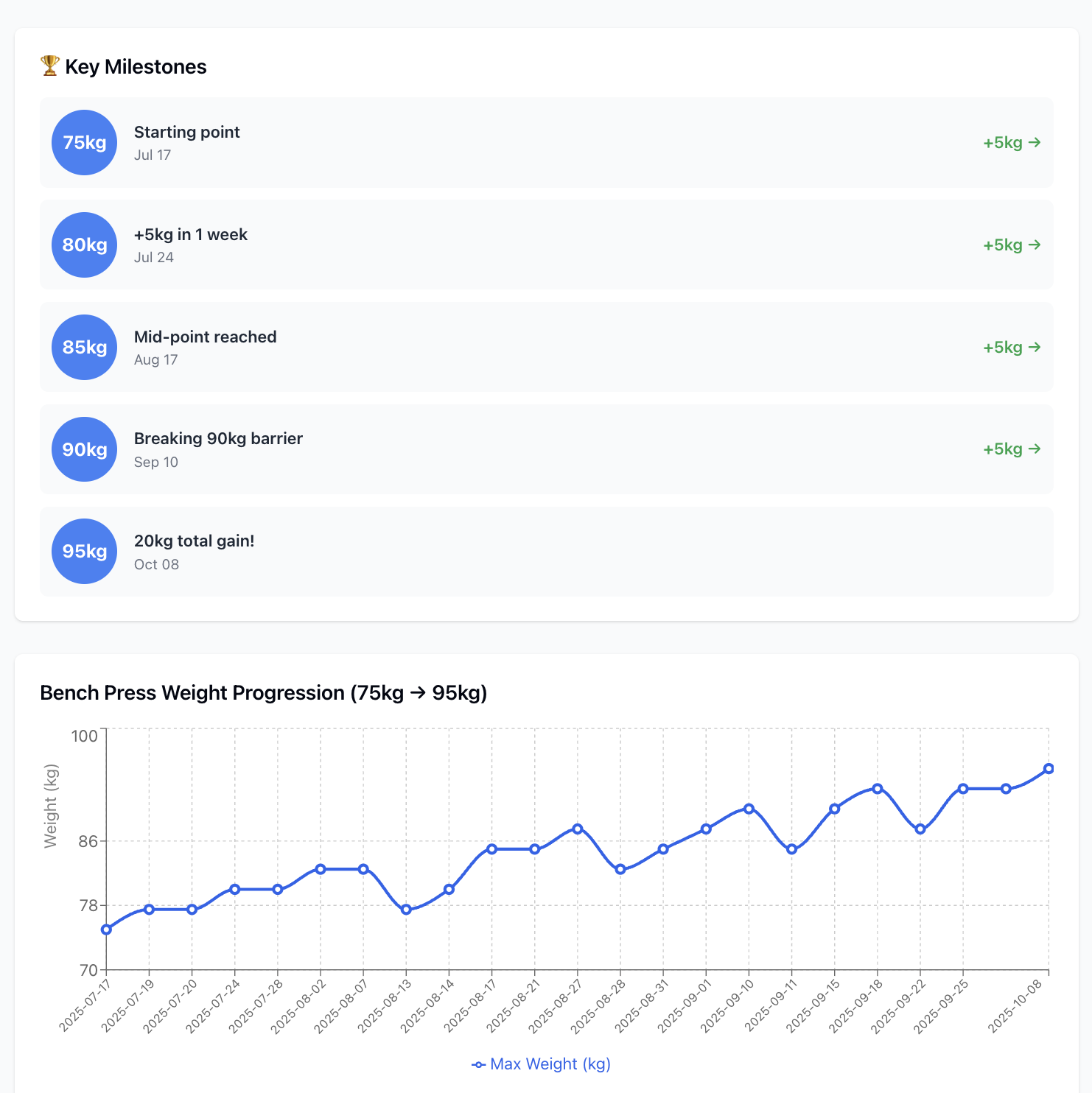
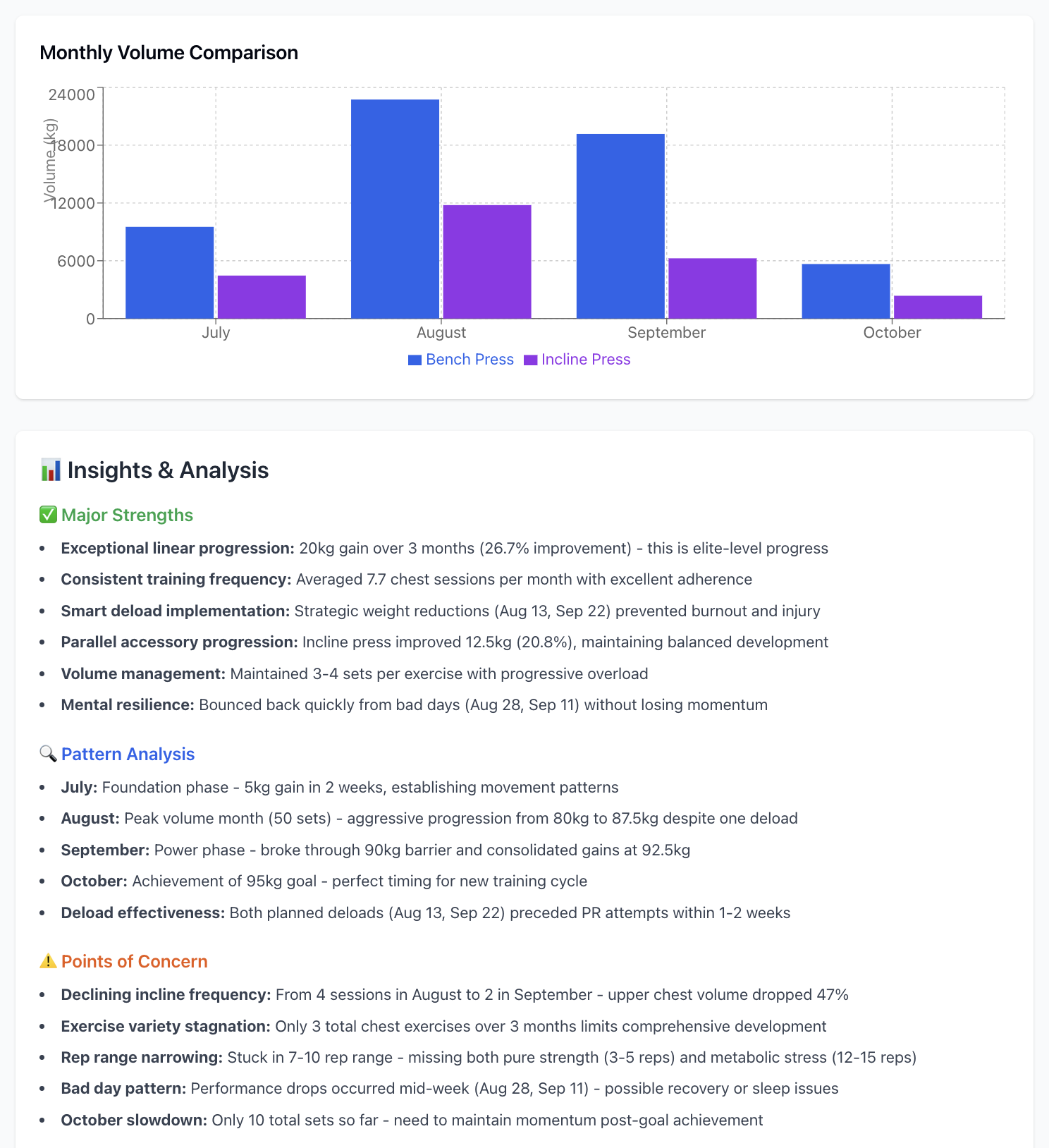
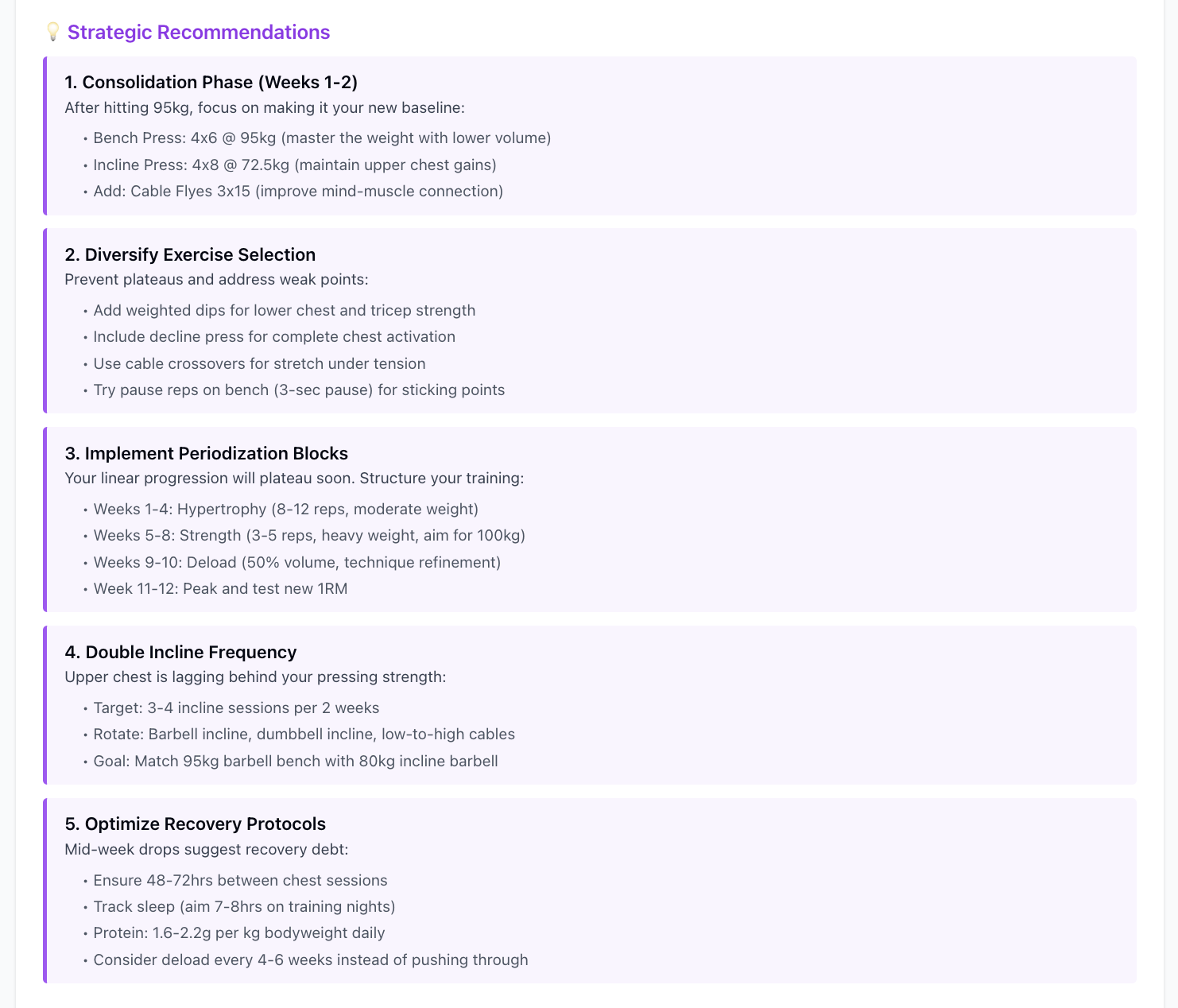
Analyse splitwise data
This one started as a way to put all the theory into practice. There are already a few Splitwise MCP servers floating around, but most of them are pretty bloated as they also focus on letting you create or update expenses, which I honestly don’t care about. Adding expenses manually is quick enough. What I actually wanted was to analyze the data and see what insights I could pull from my spending patterns and how my expenses evolve over time.
I also took a slightly different approach to handling data compared to most Splitwise MCPs. From the project README:
"Initially, the project relied on making real-time API calls to the Splitwise service, which led to high latency, even for simple LLM queries. To address this, the architecture was updated to first sync all Splitwise data into a local SQLite database. The MCP server then operates directly on this local data source. Since Splitwise data changes infrequently and is mostly append-only, this approach significantly improves performance and was a fair tradeoff."
Code files as data source
My current employer is pretty open to using AI agents as dev copilots. We’ve got subscriptions to tools like Windsurf and others. My team’s codebase is a big monolith with a ton of moving parts, so a recurring part of my workflow is selecting a chunk of code I want to explore, sending it as a prompt to Windsurf or Cursor, and then manually adding extra context, usually by linking a few other related files.
The annoying part is when the AI starts pulling in irrelevant files and pollutes its context. When that happens, I end up switching to vanilla Claude or ChatGPT and manually copy-pasting all the relevant files to rebuild the context. It’s tedious, but I’ve learned that giving proper context makes a huge difference. Without it, the model just hallucinates more often than not.
After repeating this cycle too many times, I finally decided to automate it. The abstraction that clicked was this: why can’t code files themselves be the data source? Once I built around that, I could manage context way more effectively.
I’ve built tools that give the LLM context about the database, main features, and infra by serving up relevant chunks of codebase files via the MCP server. I didn’t want to spend more time building this MCP than doing my actual job, so I designed it to be easy to extend. For complex features, there are custom tools with some written context, but for simpler ones, there’s a general tool that serves 1–2 key files needed to understand how the feature works. Extending it is as simple as adding a couple of lines in a YAML file.
Since this MCP includes some of my employer’s business logic, I can’t open-source it. But if you often find yourself manually managing context for your AI discussions, I’d definitely recommend giving this idea a try.
Update(18/10/2025): After Claude released their "Skills" feature, I gave it a shot and honestly, it's way better than maintaining an MCP server for this use case. Skills let you package domain specific knowledge into reusable modules that Claude can reference during conversations.
The main advantages: zero maintenance overhead, native integration with Claude's context management, and updating a skill just requires updating markdown files. For managing codebase context in AI conversations, skills hit the sweet spot between manual copy pasting and building custom tooling.
I still believe that MCP aren't obsolete. They're still valuable when you need dynamic data access and the first 2 usecases that we talked about above are best solved by an MCP.